CS231n - 역전파
1. computational graph
- layer가 여러 개인 어떤 neural network를 최적화하려면 주어진 훈련 데이터셋에 대하여 갖는 loss와 그때 각 layer의 가중치 행렬의 gradient를 계산하고 가중치 행렬의 각 성분을 수정하는 과정을 여러 번 거쳐야 한다. 이때 가중치 행렬의 gradient를 구하는 과정을 최대한 간단하게 구현하기 위해, 먼저 둘 이상의 변수를 입력으로 갖는 어떤 함수 \(f\)의 식과 특정한 변수가 입력으로 주어질 때 입력으로 주어진 변수를 이용해 함수값을 계산하는 과정을 생각하자. \(f\)의 각 연산자를 노드로, 말단노드는 입력으로 주어지는 변수로 하는 그래프를 그릴 수 있으며 이러한 그래프를 computational graph라 한다.
- computational graph에서 말단노드로 주어지는 변수에 대한 그 그래프의 함수값은 두 말단노드에 대한 연산값을 상위노드 위치에 쓰는 식으로 아래에서부터 위로 올라가면서 구할 수 있다. 이를 흔히 forward pass라 한다.
2. 주어진 입력에 대한 gradient 구하기
1) backpropagation
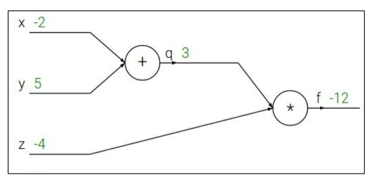
- \(f(x, y, z) = (x+y)z\)라는 간단한 함수에 입력으로 \((x, y, z) = (-2, 5, -4)\)가 주어진다 할 때 \({\partial f \over \partial x}, {\partial f \over \partial y}, {\partial f \over \partial z}\)를 구하는 과정에 대해 생각해 보자.
-
최상위노드 *의 관점에서 볼 때 한쪽 자식이 \(x+y\)인데, 편의상 \(x+y=q\)로 정의하여 * 노드가 두 자식 \(q, z\)을 갖는다고 생각하자. 이렇게 보면 \({\partial f \over \partial z} = q = 3, {\partial f \over \partial q} = z = -4\)이다.
- computational graph에서 * 노드는 이처럼 한쪽 자식의 값이 그대로 다른쪽 자식의 gradient가 된다. 이를 두고 * 노드를 흔히 gradient switcher라고도 한다.
-
+ 노드의 관점에서 볼 때 \({\partial q \over \partial x} = {\partial q \over \partial y} = 1\)인데, \({\partial f \over \partial q} = -4\)이라 했으므로 chain rule에 의해 \({\partial f \over \partial x} = {\partial f \over \partial y} = -4\)가 된다.
-
computational graph에서 + 노드의 자식노드들은 이처럼 부모노드의 gradient를 그대로 내려보낸다. 이를 두고 + 노드를 흔히 gradient distributor라고도 한다.
-
+ 노드는 최상위노드가 아닌데, 이처럼 최상위노드가 아닌 노드의 관점에서 보았을 때 그 노드의 두 자식노드가 그 노드에 대해 갖는 gradient를 local gradient라 하며, 그 노드의 부모노드에서 그 노드로 내려오는 gradient를 upstream gradient라 한다.
-
- 이처럼 computational graph에서 forward pass를 통해 각 노드에 해당하는 연산값이 미리 주어진다면, 최상위노드에서부터 거꾸로 하위노드로 내려가면서 각 노드가 갖는 gradient를 계산할 수 있다. 이러한 방식으로 최상위노드에서부터 말단노드까지 내려가며 gradient를 계산하는 것을 backpropagation이라 한다.
* max() 연산을 수행하는 노드는 두 자식노드 중 더 큰 값을 갖는 자식노드에게 upstream gradient를 내려보내고 다른쪽 자식노드에게는 gradient로 0을 내려보낸다. 이러한 기능을 두고 max() 노드를 흔히 gradient router라고도 한다.
* 어떤 함수의 경우에는 하나의 노드가 둘 이상의 부모노드를 갖는 경우도 있다. 이때 그 노드의 gradient는 그 노드의 모든 upstream gradient의 합이다.
2) 복잡한 연산의 computational graph와 backpropagation
- 역수나 지수연산 같은 연산을 여럿 포함하는 함수를 computational graph로 표현할 경우 자식이 하나인 노드들이 여럿이 줄지어 나타나는 경우를 볼 수 있다. 예를 들어, sigmoid 함수 \(\sigma(x) = { 1 \over {1 + e^{-x}}}\)의 computational graph는 아래와 같이 표현된다.

- 수학지식을 활용하면 이처럼 복잡한 연산을 포함하는 함수의 gradient를 훨씬 빠른 속도로 구할 수 있다. 예를 들어 sigmoid 함수의 gradient는 \( {\partial \sigma(x) \over \partial x} = (1 - \sigma(x) ) \sigma(x) \) 로 쓸 수 있으며, 이를 computational graph로 표현할 경우 두 단계의 연산으로 gradient가 구해짐을 알 수 있다. 딥러닝에서는 이처럼 수학지식을 활용하면 연산량을 획기적으로 줄일 수 있는 경우가 많다.
3) 입력으로 벡터를 갖는 함수의 bakcpropagation
- 입력으로 벡터를 갖는 함수의 computational graph의 경우에도 대부분의 경우가 입력으로 실수가 들어오는 함수의 경우와 같다. 단, gradient라는 것이 벡터의 스칼라 변수에 대한 도함수를 구한 것이었다는 점을 생각하면, 벡터 computational graph의 경우 입력으로 스칼라를 갖는 함수의 computational graph에서 gradient를 계산했던 것과 같은 연산(벡터의 벡터 변수에 대한 도함수 구하기)을 하는 경우에는 그 도함수로 가로세로가 그 벡터와 크기가 같은 Jacobian matrix가 나온다는 점이 스칼라 computational graph와 다르다. 따라서 스칼라 computational graph에 비해 도함수의 차원이 제곱배가 돼버려 연산량이 어마어마하게 늘어난다.
- 다만 함수의 형태에 따라 연산량이 그렇게 크게 늘어나지는 않는 경우도 있다. 예를 들어 \(f(\mathbf{x}, W) = max(0, W \mathbf{x})\)는 Jacobian matrix가 대각행렬이 되어 대각선 성분만 고려하면 된다.