베이즈 정리와 MLE
1. 베이즈 정리
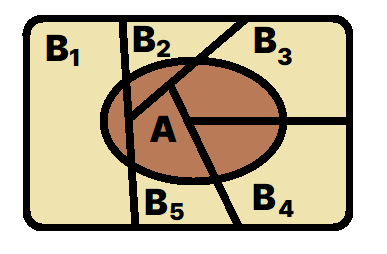
- 어떤 표본공간을 사건 \(B_1, \cdots, B_n\)이 각각 분할하고 각 사건 \(B_i\)가 일어날 확률(‘사전확률’, \(P(B_i)\))과 \(P(A \mid B_i)\)의 값(‘우도’)을 모두 알고 있을 때(단, \(i = 1, \cdots, n\)), \(P(B_r \mid A)\)의 값(‘사후확률’)을 다음 식을 계산해 얻을 수 있다.
\[P(B_r \mid A) = { {P(B_r \cap A )} \over {P(A)} } = { {P(B_r)P(A \mid B_r)} \over {\sum_{i=1}^{n} P(B_i) P(A \mid B_i)} }\]- 위 식에서 \(P(B_1), \cdots, P(B_n)\)는 사전에 주어지며, 뒤늦게 \(A\)라는 사건이 일어났을 때 그 사건이 \(B_i\)라는 사건을 전제로 하는 상황에서 일어날 확률(\(P(A \mid B_i)\))은 ‘밀도추정법(density estimation)’으로 대략적으로 구할 수 있다. 베이즈 정리는 이와 같은 확률들을 알고 있을 때, 뒤늦게 \(A\)라는 사건이 일어났을 때 그 사건이 \(B_r\)이라는 사건을 원인으로 할 확률(\(P(B_r \mid A)\))을 구하는 일종의 ‘원인의 확률 추론’ 방법이라고 생각할 수 있다.
- 머신러닝의 분류문제라는 관점에서 생각해 보면, \(A\)라는 인풋은 새로 제시된 테스트 케이스고, \(B_1, \cdots, B_n\)는 \(A\)라는 인풋이 분류되어야 할 \(n\)개의 클래스라고 생각할 수 있다. 분류문제의 관심사는 \(A\)가 \(B_1, \cdots, B_n\) 각각에 속할 확률(\(P(B_i \mid A)\))을 알아내는 것인데, 베이즈 정리를 이용하면 이 확률을 \(P(B_i)\)와 \(P(A \mid B_i)\)만을 이용하여 구할 수 있다.
2. 최대우도추정법(MLE, maximum likelihood estimation)
- 어떤 사건 \(A\)가 일어날 정확한 확률을 알지는 못하지만 표본을 추출하는 등의 방법을 통해 그 대략적 분포를 구했을 때, 그 분포를 통해 ‘\(A\)의 확률로 추론한 값’에 부여하는 일종의 확률을 우도(likelihood)라 한다. 예를 들어 어떤 주사위를 던져 1이 나오는 사건(\(A\))의 정확한 확률(\(\mu\))을 알지는 못하지만 독립시행의 확률분포는 베르누이 분포임을 알고 있으므로 ‘주사위를 10번 던져 1이 3번 나오는 사건(\(B\))’의 확률은 \({10 \choose 3} \mu^3 (1-\mu)^7\)임을 안다. 이를 미지의 변수 \(\mu\)에 대하여 계산된 \(B\)의 확률이라 하여 \(P(X \mid \mu)\)로 표시하는데, 거꾸로 생각하면 \(\mu\)는 \(B\)라는 사건을 통해 \(A\)의 확률로 추론한 값이므로 \(P(B \mid \mu)\)를 \(\mu\)의 함수라고 볼 수도 있다. 이처럼 ‘확률로 추론되는 값’을 변수로 갖는 함수를 우도함수(likelihood function)라 한다.
- 어떤 확률의 우도가 크다는 것은 그 확률이 \(A\)의 확률일 개연성이 높다는 것을 뜻한다. 우도를 최대로 하는 확률이 \(A\)의 확률이다. 이처럼 우도를 최대로 하는 확률을 구하여 \(A\)의 확률을 구하는 방법을 최대우도추정법이라 한다. 우도함수는 흔히 \(L(\theta)\)로 쓰므로, 최대우도추정법으로 구한 \(\theta\)의 최댓값 \(\hat{\theta} = \mathrm{argmax}_\theta L(\theta)\) 으로 쓸 수 있다.
3. 빈도주의와 베이즈주의
-
어떤 사건이 반복 가능할 때, 사건 결과가 만드는 확률분포를 ‘각 결과의 빈도수별 확률의 분포’라는 관점에서 해석하는 관점을 빈도주의(frequentist)라 한다. 빈도주의 관점에서는 모르는 확률을 최대우도추정법 같은 방법을 통해 구하는데, 이 경우 확률 추론을 위해 추출한 표본이 극단적 편향을 갖는 경우 확률 또한 그에 맞춰 편향된 확률이 추론된다는 단점이 있다.
-
어떤 사건이 반복 가능한 사건은 아니지만 그 사건의 원인이 발생할 확률 등 여러 정량적으로 표현되는 정보를 활용해 그 사건이 발생할 확률을 계산할 수 있을 때, 이처럼 그 사건의 확률을 정량적 정보를 활용해 계산하는 관점을 베이즈주의(Beysian)라 한다. 베이즈주의 관점에서는 모르는 확률을 베이즈 정리를 통해 구하며 이 경우 빈도주의에서와 같은 문제가 발생하지는 않는다.